Select your language


顯微鏡影像的 CNNs:深度解析 AI 類神經網路在影像分析中的應用
如果你有關注人工智慧圖像分析(AI-Powered Image Analysis)的熱門話題,那麼「CNN」這個詞彙你大概已經聽過好幾百遍了,可能比網路上貓咪的照片還多。簡單來說,卷積神經網路(Convolutional Neural Network, CNN)就是一種特別的類神經網路(Neural Network)。它在傳統的「全連接層」(你可以把它想成是做最終決策的大腦決策中心) 前面,加了一個聰明又擅長處理圖像的前端(Front End)。這個前端(Front End)能讓模型(Model)在試圖辨識圖片內容之前,先一步將形狀(Shape)、紋理(Texture)和邊緣(Edge)這些細節給抽離出來。正是因為有了這個前端特徵提取器(Front-End Feature Extractor)和後端分類器(Back-End Classifier)的巧妙結合,讓 CNN 成為現代顯微鏡分析中不可或缺的工具,這也是它為什麼值得我們好好去了解的原因。
為何圖像對演算法來說是項挑戰? Why Images Challenge Algorithms?
乍看之下,影像分割(Image Segmentation)可能看似簡單:識別圖片中的形狀並畫出邊界。但真實世界的顯微鏡圖像通常是單通道灰階(Single-Channel Gray Scale),充滿了模糊的邊緣、重疊的細胞或纖細的纖維。單一的全局閾值(Single Global Threshold)無法應對這種混亂,因此基於規則的演算法(Rule-Based Algorithms)會因此失效。
如果你曾親身經歷過這些痛點,可以參考我們關於《圖像分析的種種困境》的文章,深入解析並探討它們發生的原因,以及說明現代 AI 工具如何提供幫助。CNNs 透過從帶有標籤的範例中學習,而非依賴固定規則,從而避開了這種僵化性。

每個 CNN 內部的兩階段流程 The Two-Stage Pipeline Inside Every CNN
| 階段 (Stage) | 作用 (What Happens) | 主要構成 (Rough Ingredients) |
|---|---|---|
| 前端:特徵提取器 Front-End: Feature Extractor |
將原始像素轉換為精簡且具資訊量的特徵圖 | 卷積 (Convolution) → ReLU → 池化 (Pooling)(重複執行) |
| 後端:分類器頭 Back-End: Classifier Head |
將這些特徵圖轉換為最終的標籤 | 一或兩個全連接 (密集) 層 |
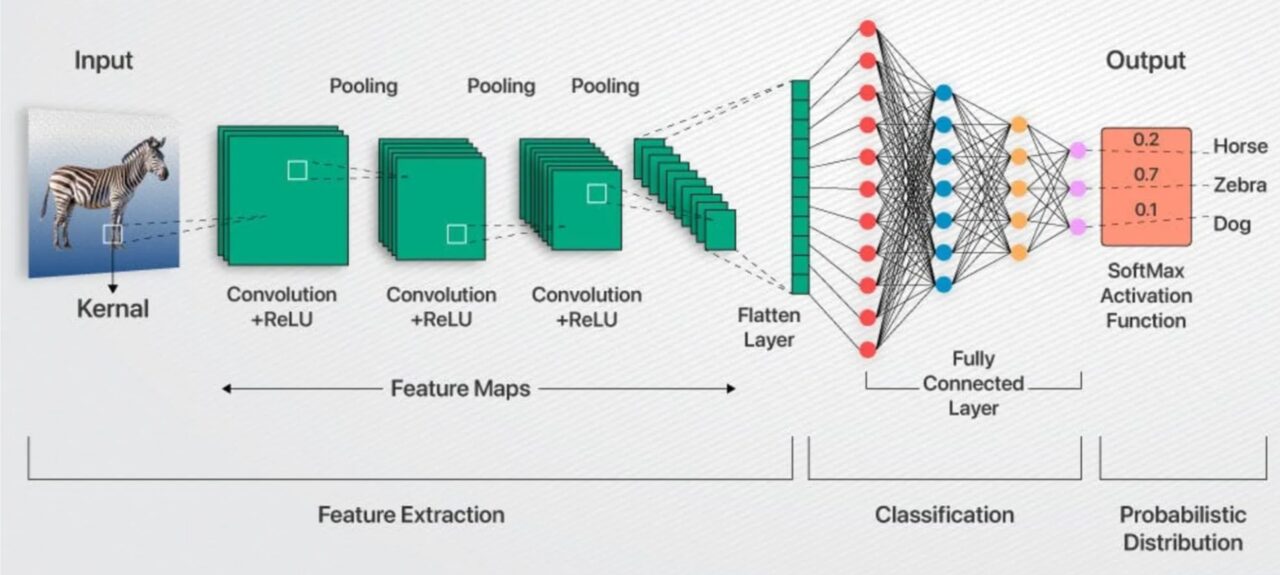
特徵提取:速成課程
卷積層(Convolutional Layers)會將可學習的濾波器(Filter)(想像成 3x3 或 5x5 的模板)在圖像的小區塊上滑動。每個濾波器(Filter)一開始都是隨機數字,但在訓練過程中,它們會逐漸變成邊緣、角落或紋理的檢測器。由於相同的濾波器(Filter)會在圖像各處滑動,因此網路能共享權重,與將每個像素連接到每個神經元相比,這樣能大幅減少參數。
每個卷積層之後通常會接著激活函數(Activation Function)——通常是 ReLU(Rectified Linear Unit,修正線性單元)——會緊跟在每個卷積層後面。ReLU 的作用很簡單,它只會保留正數值,並將負數值歸零。這能為模型增加一點必要的非線性,這樣堆疊起來的層次才能夠模擬曲線、斑點,或是介於兩者之間的任何彎曲形狀。
池化層(Pooling Layers)(最大池化或平均池化)會縮小特徵圖。想像一下,它會保留每個 2x2 區塊中最亮的像素,這能減少記憶體使用量、加快運算速度,並賦予模型一定程度的平移容忍度(Translation Tolerance)——如果您的細胞核移動了幾個像素,池化後的訊號幾乎不會改變。
層層遞進,網路從「嘿,那是一條邊緣」進化到「那個群體看起來很像細胞核」。早期層檢測簡單的形狀;更深層的則能捕捉完整的細胞。
這為什麼重要?特徵提取(Feature Extraction)讓分類器(Classifier)不必再盯著 262,144 個原始像素值(對於 512x512 的圖像),而是將一組整齊的、可能只有幾千個高階描述符(High-Level Descriptor)交給它,這些描述符(Descriptor)會大聲宣告「這裡有細胞核,那裡是背景」。

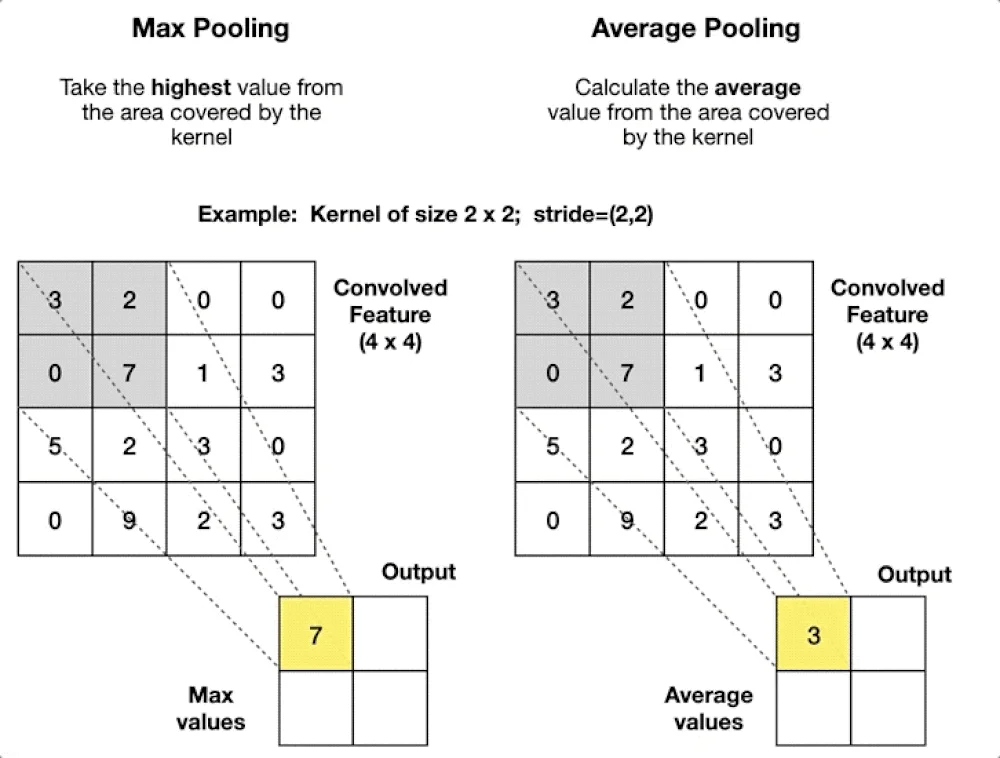
分類 (Classification) - 全連接的最終章
當影像被精煉成整齊的向量(Vector)後,就輪到全連接層(Dense Layers)接手了。
- 扁平化(Flattening):將堆疊的三維特徵圖(Feature Maps)展開成一維向量(Vector),可以想像一下類似把睡袋攤開的這個過程。
- 全連接層(Dense Layers,又稱Fully Connected Layers):將每個輸入值連接到每個神經元(Neuron),每個連接都帶有可訓練的權重(Trainable Weight)和一個偏差值(Bias)。
- 激活與輸出(Activation & Output):另一個 ReLU 激活函數會維持非線性流動(Non-Linearity Flowing),然後將原始分數轉換為機率。
全連接層(Dense Layers)擅長將不同的線索——紋理(Texture)、形狀(Shape)、上下文(Context,或譯為前後關系)——融合成一個最終判斷(Verdict)。那代價是什麼呢?它們需要大量的參數,所以我們讓它們保持精簡,並將它們置於輕量且高效的特徵提取器(Feature Extractor)之後。
若想進一步了解電腦視覺(Computer Vision)中的卷積神經網路(Convolutional Neural Networks, CNNs)的知識,史丹佛大學 CS231n 課程提供了嚴謹、講座形式的深度解析。
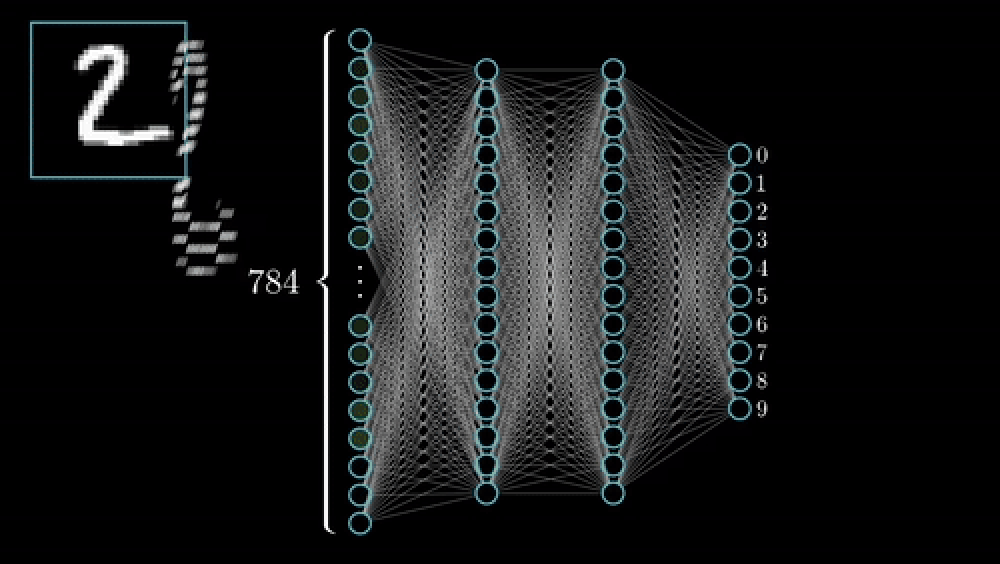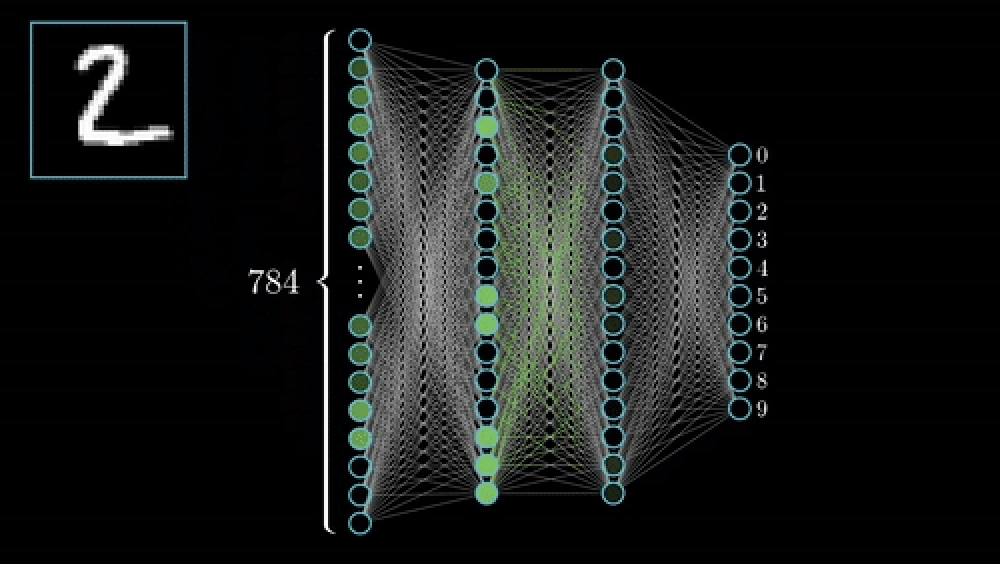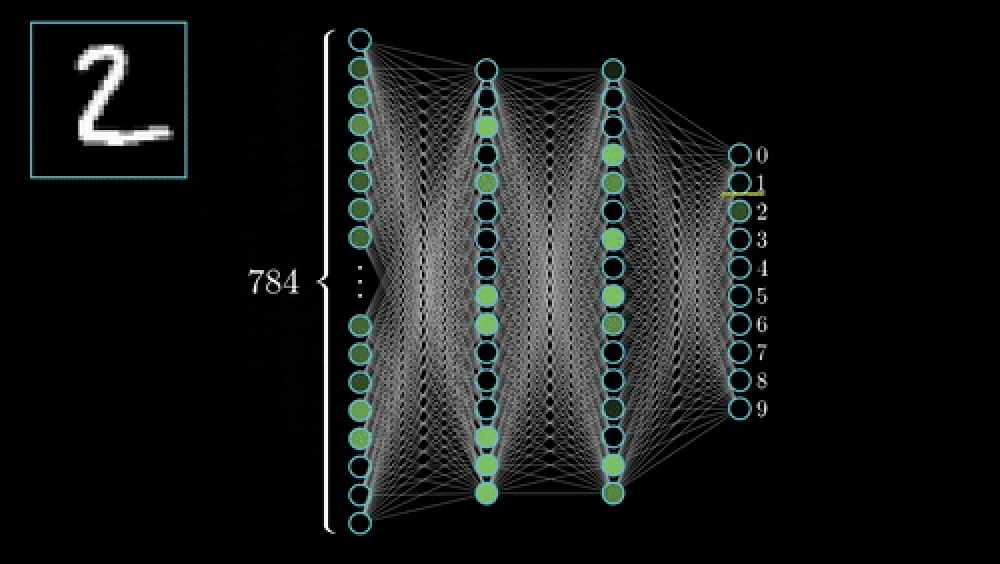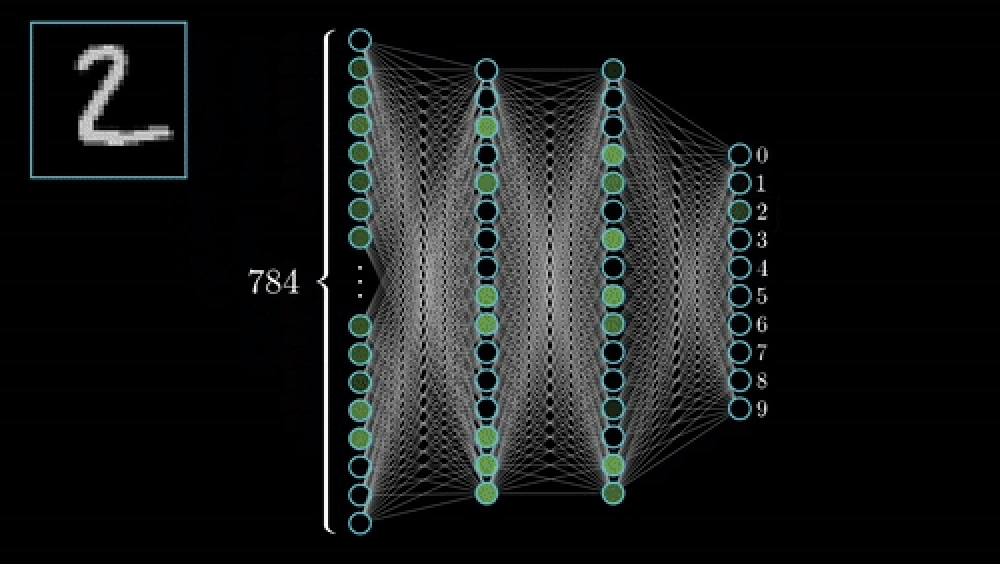
CNN 訓練基礎:逐步指南 CNN Training Basics: A Step-by-Step Guide
- 標記 (Label):由人類(也就是您)在範例圖像上繪製輪廓(Outlines)或遮罩(Mask)。
- 前向傳播 (Forward Pass):網路進行預測。
- 損失函數 (Loss Function):一個衡量錯誤的指標,會計算預測的錯誤程度,例如:交叉熵(Cross-Entropy)或骰子損失(Dice Loss)。
- 反向傳播 (Back-Propagation):梯度向後傳遞,微調權重以減少損失(Loss)。
- 重複多個訓練週期 (Epochs):每個循環都會優化濾波器(Filters),邊緣變得更清晰,細胞核偵測器也逐漸成形,直到性能趨於穩定。
網路會研究少量、隨機打亂的批次圖像,這樣它就不會以固定的順序學習。一個學習率撥盤控制著它的步長,如果太大使它錯過答案,太小則會讓它進展緩慢。一個單獨的驗證集圖像(這些圖像在訓練過程中從未見過)會顯示模型是否真的在學習,還是只是在記憶。
它還會透過翻轉、旋轉或增亮圖像來擴充數據,這樣模型就能以新的姿勢遇到熟悉的物件。經過足夠的回合後,曾經隨機的連接會演變成分層模式偵測器( Layered Pattern Detectors),專為您的圖像進行調整。
若想了解相同訓練循環在醫學影像中的詳細介紹及常見問題,以及小型數據集和過度擬合等常見問題,請參閱 Yamashita 等人的《卷積神經網路:放射學中的概述與應用》。
總結:聚焦核心 Final Thoughts; Bringing It All into Focus
卷積神經網路(Convolutional Neural Networks,CNNs)之所以能在顯微鏡影像分析中取得成功,原因與經驗豐富的顯微鏡專家相同,它們都是從尋找視覺的基本線索(邊緣、角落、紋理)開始,然後將這些線索組合成連貫的物件和類別。
得益於這種資料驅動的提取方式,您現在可以處理各種不同的任務,例如:測量纖維厚度、執行免標記細胞計數,或在穿透式電子顯微鏡(TEM)影像中分割細胞核和粒線體,所有這些都不需要手動調整閾值。這些模型能有效處理不均勻的光線、微弱的染色和雜亂的背景,並且隨著您提供更多具代表性的範例而持續改進。
簡而言之,CNNs 將混亂的真實世界圖像轉化為可靠、可重現的測量結果,讓您無需在每次條件變化時都重新編寫規則。
重點整理 (Key Takeaways)
- 兩階段流程:CNNs 首先會提取邊緣和紋理,然後再對其發現的內容進行標記。
- 透過範例訓練:過程包括標記(Label) → 猜測(Guess) → 測量誤差(Measure Error) → 調整權重(Adjust Weights),並透過資料隨機和增強進行多個訓練週期(Epochs )。
- 應對真實世界的混亂:即使在染色微弱、光線不均或物體接觸的情況下,仍能保持準確。
- 適用於多種任務:同一個網路可以用於計算細胞、測量纖維厚度或分割細胞核和粒線體。
- 節省時間:一旦訓練完成,它能提供快速、可重複的測量,無需無止盡地調整閾值。
VAT Number: 28376870
Contact us: service@totalsmart.com.tw
Business Address: Rm7, 10FL, No.262, Sec. 2, Henan Rd., Xitun Dist., Taichung City 40744, Taiwan (R.O.C.)
Monday – Friday
8:30 am – 5:30 pm CST
TEL : +886-4-27080265 | FAX : +886-4-27080263
Taipei OfficeTEL : +886-2-89924292 | FAX : +886-2-89929426
Websitehttps://www.totalsmart.tw (TW ∣ CN ∣ EN)
https://www.totalsmart.com.tw (TW)
Copyright © 2026 Total-Smart Technology Co., Ltd. All Rights Reserved. | Privacy Policy | Terms of Use