選擇你的語言


人工智慧顯微鏡影像分析入門指南
| Image-Pro 影像分析軟體 | MA-Pro 金相分析軟體 | 金相材料分析應用介紹 | 金相分析相關國際標準規範 |
| 圖像分析的五大困境 | 人工智慧顯微鏡影像分析初學者指南 | 深度解析 AI 類神經網路在影像分析中的應用 |
提供您精確且專業的AI影像分析技術指南,幫助研究人員和工程師將更多精力投注於數據分析,而不是浪費時間在處理繁瑣的邊界標記工作上。
為何要將 AI 導入你的顯微鏡工作流程?
Why Bring AI into Your Microscope Workflow?
無論您的需求是識別細胞結構(Cellular Structures)、評估金屬材料的晶粒尺寸(Grain Size)還是檢查製造零件的品質,全都面臨著一個共同的挑戰:原始顯微鏡圖像很少能夠直接轉換為所需的表格數據。
傳統的影像處理(Image Processing)方法,例如,閾值(Thresholds)判斷、形態濾波器(Morphological Filters)和手繪輪廓(Hand-Drawn Outlines)等,在面對影像雜訊較多、對比度低、密集分布或形狀異常的分析目標時,軟體處理速度就會變慢。相比之下,深度學習模型(Deep Learning Models)能夠直接從代表性數據中,學習分析目標在視覺上的複雜性,並運用所「學習」的模式匹配能力,不做任何改變且持續穩定地處理成千上萬張影像。
AI影像分析技術帶來三大優勢:
- 速度 (Speed):可在數秒內分割或分類數百張影像,省去手動描繪輪廓的繁瑣過程。
- 一致性 (Consistency):凌晨 2 點的結果與下午 2 點的結果相同,模型不會疲勞或產生偏差。
- 敏感度 (Sensitivity):能識別細微的外顯特徵(Phenotypes)或微弱的缺陷,而傳統的基於規則的濾波器(Rule-Based Filters)則容易忽略這些細節。
簡而言之,本指南將解釋 AI 的基本概念,幫助您判斷何時或者如何在自己的實驗室或生產線中採用 AI 影像分析技術。

圖 1. 透射式電子顯微鏡(Transmission Electron Microscope)所拍攝的數位影像使用 AI 深度學習(Deep Learning)進行影像分割(Image Segmentation),最終影像分析(Image Analysis)結果標示出各種不同的細胞內結構,而傳統的灰階範圍選取方法則難以精確描繪這些結構。
關鍵術語
Key Terms You’ll See
在我們深入探討之前,讓我們先了解幾個關鍵詞定義,以確保本文內容清晰易懂。
| 關鍵詞 (Term) | 工作定義 (Working Definition) |
| 人工智慧 Artificial Intelligence (AI) |
能夠模擬人類層級模式(Human-Level Pattern)進行識別(Recognition)或決策(Decision)過程的演算法。 |
| 機器學習 Machine Learning (ML) |
屬於人工智慧技術的分支,模型(Models)在訓練過程中接觸到的大量數據與多樣性,這個概念與數據可見性(Data Visibility)或數據呈現(Data Presentation)密切相關,且影響模型的學習能力與泛化能力。其中模型(Models)會透過數據曝光(Data Exposure)來提升自動化性能。 |
| 深度學習 Deep Learning |
機器學習堆疊許多神經層來捕捉複雜的影像結構。 這個描述指的是深度學習模型,特別是深度神經網路,它使用多層神經網路來分析和理解影像中的細微結構。 |
| 神經網路 Neural Network |
一種分層模型(Layered Model),能從數據(如,視覺、文本、信號等)中學習特徵。這個描述是機器學習中的深度神經網路,它透過多層結構逐步抽取資訊中的重要特徵,廣泛應用於影像辨識、自然語言處理和訊號分析等領域。 |
| 卷積神經網路 Convolutional Neural Network (CNN) |
一種神經網路(Neural Network),其層使用卷積濾波器(Convolution Filters),使其在影像處理方面特別有效。這類神經網路透過卷積運算提取影像中的關鍵特徵,使其在物件識別、醫學影像分析和自動駕駛等領域有廣泛應用。 |
| 分割 Segmentation |
將影像分割成有意義的區域(Region),如細胞(Cells)、晶粒(Grains)、纖維(Fibers)、焊點(Solder Joints)等目標。這個過程通常稱為影像分割(Image Segmentation),在電腦視覺和材料科學領域中非常重要。它能幫助識別影像中的不同結構,使分析更加精確,例如在顯微鏡影像中區分細胞類型或在工業檢測中辨識焊接品質。 |
| 標註 Annotation |
人工繪製的輪廓或標註,用於訓練神經網路。經過整理後,它們成為「真實標註(Ground Truth)」數據。 這通常稱為標註(Annotation),是機器學習訓練過程中的關鍵步驟。標註者手動標註影像中的物件、邊界或感興趣的區域,確保模型學習準確的特徵。經過整理和驗證後,這些標註數據成為真實標註(Ground Truth),用來評估模型的準確性。 |
| 訓練週期 Epoch |
在機器學習和深度學習中,Epoch(訓練週期)指的是模型對整個訓練數據集進行一次完整學習的過程,由於現代深度學習技術的計算效率提升,許多模型可以在短時間內完成一個 Epoch(訓練週期),通常以秒為單位計算,而非小時。換句話說,當所有訓練樣本都被模型學習一次,就完成了一個Epoch(訓練週期)。 |
| 交集比聯集 Intersection over Union (IoU) |
量化分割品質(Quantifies Segmentation Quality)的方法,透過計算AI 掩碼(AI Mask,或譯為遮罩,指人工智慧生成的遮罩)與「真實標註(Ground Truth)」的重疊區域,並將其除以兩者的總覆蓋面積。分數範圍從 0(完全不匹配) 到 1(完美匹配),通常 0.8 或更高的值,則被視為可靠的結果。這種指標常用於評估影像分割模型的準確性,確保 AI 能夠準確識別目標區域。在電腦視覺和物件偵測領域,IoU 是一個衡量預測邊界框與真實邊界框重疊程度的指標。 |
表 1. 本文中使用的關鍵術語詞彙表,這些術語與人工智慧(AI)和深度學習(Deep Learning)主題相關。括號中的所有縮寫將在本文中以簡化形式使用。

圖 2. 顯示人工智慧(Artificial Intelligence, AI)演進的時間軸:早期的規則導向系統(Rule-Based Systems)方法在1980年代讓位於機器學習(Machine Learning),後來到2010年代至2020年代間發展為深度學習(Deep Learning),此時間軸展示了 AI 技術的發展歷程。這些技術的進步使 AI 能夠更準確地理解數據、預測結果,並在各種應用領域中發揮重要作用。
歷史概況
A Brief Historical Snapshot
教會機器「思考(Think)」的想法並不新鮮;它可以追溯到西元1956年的達特茅斯會議(Dartmouth Conference),人工智慧(Artificial Intelligence, AI) 一詞就是在這次會議上誕生的。正是在這次會議上,像約翰·麥卡錫(John McCarthy)和馬文·明斯基(Marvin Minsky)這樣的先驅提出了模擬機器學習的雄心壯志。當時,一些早期的成功案例,例如弗蘭克·羅森布拉特(Frank Rosenblatt)在西元1958年提出的感知器(Perceptron),暗示了未來的可能性,但受限於當時硬體的限制使得該領域進展緩慢。
時序快轉到 2010 年代繪圖處理器(GPU)的蓬勃發展,突然間基於大數據(Big Data)和大規模平行處理(Massive Parallel Processing)的深度學習(Deep Learning)技術突飛猛進,將數十年的理論轉化為日常現實。如今,深度學習理論(Deep-Learning Theory)已成為實用的工具,能夠在短短數分鐘內處理高解析度顯微鏡堆疊影像。
為何選擇人工智慧? ——五個持續存在的難題
Why AI? — Five Persistent Pain Points
想了解人工智慧(AI)為何如此重要,最簡單的方法就是回想你已經很熟悉的那些惱人痛點。
在〈圖像分析的五大困境——以及如何解決〉(Five Frustrating Realities of Image Analysis—And How to Fix Them) 的文章中,我們總結了常見的障礙:結果不一(Variable Results)、脆弱的腳本(Fragile Scripts)、處理量瓶頸(Throughput Bottlenecks)、陡峭的學習曲線(Steep Learning Curves)以及再現性差距(Reproducibility Gaps)。每個痛點都源於依賴操作者主觀判斷的規則導向步驟(Rule-Based Steps)(例如:操作者的滑鼠點擊方式,或是他們操作疲勞的程度)。
人工智慧(AI)透過直接從圖像資料中學習模式、統一應用這些模式並在幾秒鐘,而不是幾小時內完成所有操作來解決這些脆弱性。
適合人工智慧的核心影像分割任務
Core Segmentation Tasks Suited to AI
由於 AI 模型是從範例中學習,而非仰賴硬性的閾值(thresholds)設定,因此它們在以下兩種關鍵的影像分割(Image Segmentation)情境中,表現優於傳統方法:
- 語義分割(Semantic Segmentation) — 語義分割會根據像素的類別進行色彩編碼(Color Codes),將像素歸類為不同類別,而非單獨的物件。在下面的範例中,一整排停放的汽車會被塗上相同的「汽車」顏色,而所有相連的樹木則會被塗上相同的「樹木」顏色。
- 實例分割(Instance Segmentation) — 實例分割會為視野中的每個物件產生一個獨立的遮罩(Mask),這樣你就能以相同的可靠性,計算和量化從細胞核到金屬晶粒或焊錫球的任何物體。在下面的範例中,一個基於 Cellpose 的模型(Model)即使在細胞互相接觸的情況下,也能將它們區分開來。

圖 3. 語意分割(Semantic Segmentation)顏色編碼的範例。
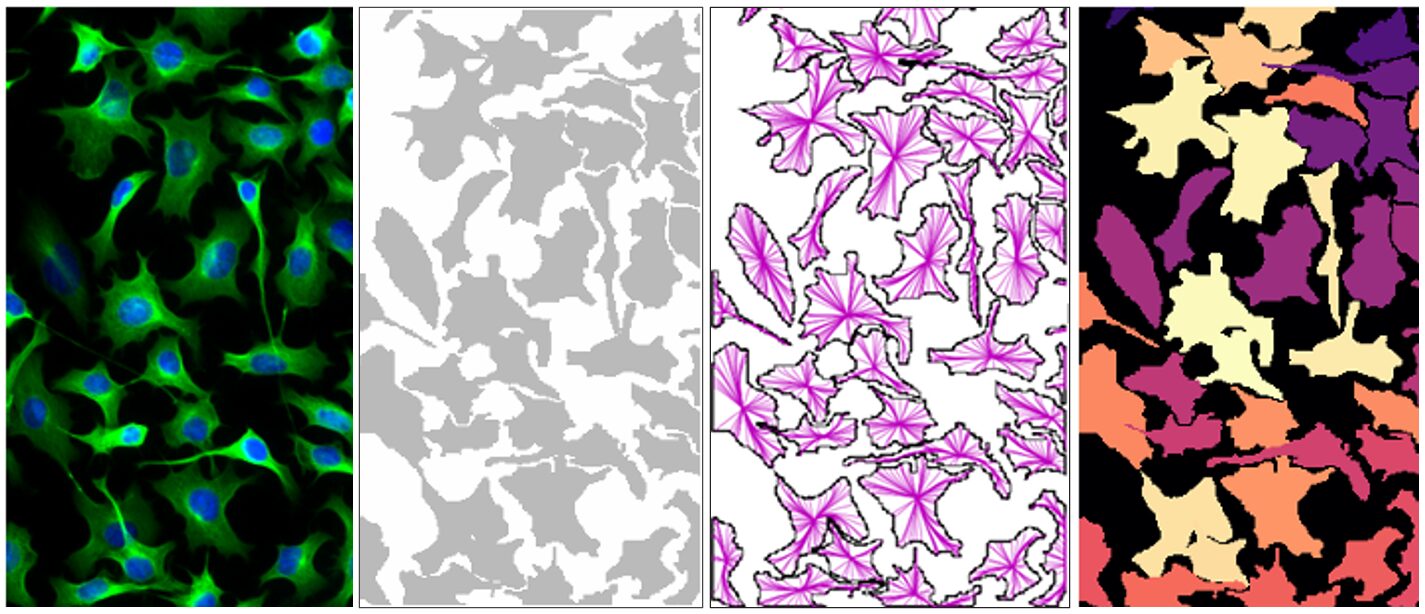
圖 4. 使用基於 Cellpose 的模型對單一細胞進行實例分割的範例。
比較研究顯示:
| 方法 Approach |
典型準確度分數 (IoU) Typical Accuracy Score |
痛苦程度 Pain Level |
| 手動描繪 Manual Tracing |
黃金標準,但速度慢,≥ 0.9 | 耗費大量時間 |
| 基於規則(Rule-Based) 閾值 ↔ 分水嶺演算法 Threshold ↔ Watershed |
≤ 0.70 | 處理雜亂影像時容易失效 |
| 傳統機器學習 (K 均值聚類) Deep Learning |
≈ 0.75 | 錯過精細邊緣 |
| AI 深度學習 CNNs AI Deep Learning CNNs |
0.85 – 0.95 | 快速 + 準確 |
表 2. 從手動追蹤到 AI 深度學習 CNNs 的不同物體辨識技術的比較以及每種技術的典型準確度和痛苦程度。


圖 5. 生命科學和材料科學應用中物體辨識技術(Object Identification Techniques)的比較。 上圖:Chick CAM Assay-從原始影像到 AI 驅動的深度學習(Deep Learning),實現精準的血管分割(Vessel Segmentation)。 下圖:DIC Water Droplets-使用 AI 增強物體檢測(Object Detection),以提高精確度和一致性。
了解卷積神經網路(CNNs)—— 現代 AI 影像分割的引擎
Understanding Convolutional Neural Networks (CNNs) — The Engine Behind Modern AI Segmentation
深度學習(Deep Learning)影像工具主要由卷積神經網路 (Convolutional Neural Networks, CNNs) 驅動,這是一種專門為圖片而非數位電子表格設計的神經網路(Neural Network)。 CNN 透過將數十個(然後是數百個)微小、可訓練的濾波器,在每個像素的行和列上滑動來學習:
- 早期層(Early layers):就像邊緣偵測器(Edge Detector)一樣,對簡單的對比和線條做出反應。
- 中間層(Middle layers):將這些邊緣組合成紋理(Texture)、斑點(Blob)或重複的圖案(Repeating Patterns)。
- 深層(Deep layers):組合出完整的形狀——細胞(Cell)、晶粒(Grain)、空隙(Void)、樹突(Dendrite)——並判斷每個像素是屬於邊界之內還是之外。
由於每個濾波器(Filter)都是直接從您標註過的範例中學習而來,因此 CNN 能自動適應各種複雜紋理,例如:模糊的粒線體(Fuzzy Mitochondria)、樹突孔洞(Dendritic Pores)或合金析出物(Alloy Precipitates),這些紋理若使用基於規則的流程,將需要無止盡地調整參數。而 U-Net 或 Mask R-CNN 等架構,只是單純地堆疊並連接這些卷積層(Convolutional Layers),就能在捕捉全局上下文的同時保留更多細節,最終產生的輪廓能接近人類的精確度,但在現代 GPU 上只需幾毫秒即可完成。
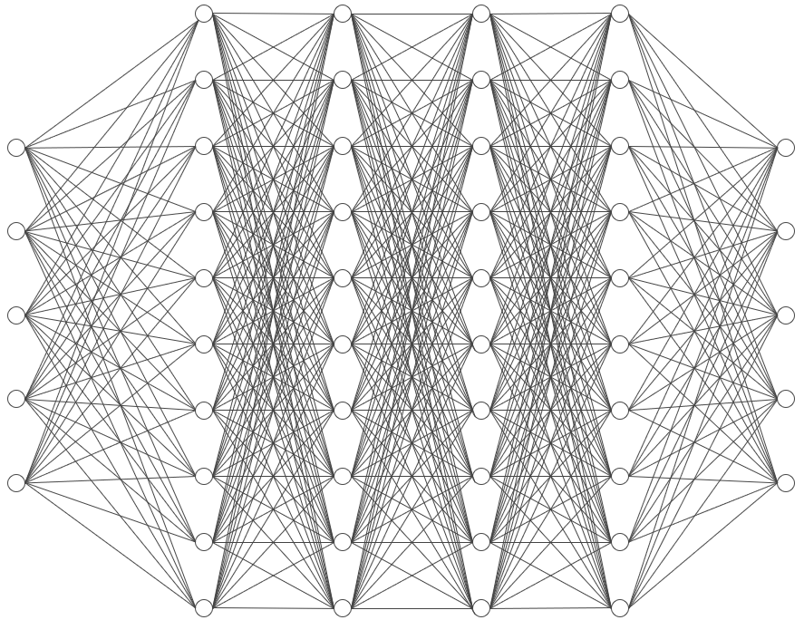
圖 6.用於分層影像學習的具有堆疊層和密集連結的深度神經網路示意圖。
人工智慧的五步驟入門工作流程
A Five-Step Starter Workflow
了解人工智慧(AI)能做什麼令人振奮的事;而知道如何實現這些功能則更能讓你掌握主動權。以下是經過驗證的五步驟路徑,讓你能在第一天就生成值得信賴的遮罩(Mask):
| 步驟 Step |
行動 Action |
實用建議 Practical Tip |
| 1) 測試預訓練模型 Test a Pre-Trained Model |
運行一個適用於您的領域模型(Domain-Appropriate Model),以獲得初步的遮罩(Mask)。 | 選擇一個能讓您接近目標的模型,即使它不完美。這能揭示需要微調的地方,並為您節省時間。 |
| 2) 複製模型 Clone Model |
建立預訓練模型(Pre-Trained Model)的副本,其中包含它從先前訓練中「學習」到的一切。 | 複製能避免更改原始預訓練模型,使其可以安全地再次使用。 |
| 3) 策略性地微調標記物件 Fine-Tune Annotations Strategically |
更正錯誤並標記所有遺漏的物件。 | 使用ROI (Region Of Interest, 感興趣區域)工具來將標記集中在較小的區域,但務必確認須標記所有物件,否則它們將被視為背景。 |
| 4) 迭代式再訓練 Iteratively Re-Train |
收集一組具代表性的影像,然後測試您複製的模型(Model),進行微調並迭代訓練,直到結果準確為止。 | 強調模糊的物件邊界,並包含所有物件,包括邊緣案例。 |
| 5) 驗證與批次處理 Validate & Batch-Process |
將 AI 遮罩與 10 張參考影像進行比較,然後處理整個資料夾。 | 保留原始、註釋和結果層以供參考。 |
表 3. 調整預訓練分割模型(Pre-Trained Segmentation Model)的五個工作流程步驟,讓您可以可靠地批次處理自己的顯微鏡影像。
透過遵循評估(Evaluate)、複製(Clone)、精修(Refine)、再訓練(Retrain)和驗證(Validate)這個嚴謹的循環,您可以將一個通用網路轉變成一個針對特定任務的專家,而無需從頭開始。這個過程能最大限度地減少手動標記(Manual Labeling),保留一個乾淨的備用模型,並在邊緣案例錯誤擴散之前穩定地將它們識別出來。實際上,這意味著您能更快地獲得可供發表的影像遮罩,對大量分析充滿信心,並將寶貴的顯微鏡時間和人力從重複的返工中解放出來,投入到發現更多新的事物。
常見陷阱與解決方案
Common Pitfalls and Their Fixes
即使流程順暢,初次使用者仍可能遇到一些陷阱。幸運的是,每個問題都有簡單的解決方法:
- 從零開始:認為總是需要建立新模型是浪費時間的。複製一個適合您的領域預訓練模型(Domain-Appropriate Pre-Trained Model)會更快。
- 遺漏標籤:跳過模糊或不完整的物件對您的模型會有反效果,因為影像中的每個物件都會參與訓練,不會被忽略。
- 物件數量過少:有時模型不夠穩健,是因為訓練集有限。它看到的「真實數據」越多,就會越穩健。
- 草率標記:標註的輪廓很重要,會影響訓練結果。放大影像並使用畫筆、橡皮擦和微調工具來建立精確的標籤。
將這些預防措施融入您的日常工作中,您就能保持進度,而不是花時間糾結於模型為何無法運作。
總結
Final Thoughts
如果您的工作流程仍依賴手動調整閾值(Threshold)或人工描繪(Manual Tracing),那您就是將數小時的時間投入到一個訓練有素的模型能在幾秒鐘內完成的任務上。導入人工智慧(AI)並不會取代您的專業知識,而是解放了它。
從一個預訓練模型(Pre-Trained Model)開始:它內建的真實數據能立即為您提供基準,並減少從零開始標註所花費的時間。然後,再加入少量您自己高品質的標籤來精煉模型。
回報是迅速的——更精確的一致性、更快的周轉時間,以及能夠探索比手動方法所允許的更大資料集的自由。簡而言之,人工智慧(AI)驅動的影像分析不只是一次技術升級;它是將更多時間用於深入洞察,減少逐像素處理雜務的實用途徑。
統一編號:28376870
服務信箱: service@totalsmart.com.tw
地址:40744 台中市西屯區河南路2段262號10樓之7
Monday – Friday
8:30 am – 5:30 pm CST
電話: +886-4-27080265 | 傳真:+886-4-27080263
台北電話: +886-2-89924292 | 傳真:+886-2-89929426
公司網站入口https://www.totalsmart.tw (繁體 ∣ 简体 ∣ English)
https://www.totalsmart.com.tw (繁體)
Copyright © 2026 Total-Smart Technology Co., Ltd. All Rights Reserved. | Privacy Policy | Terms of Use